colpali: PDF 내용을 text로 chunking 안하고 이미지로 처리하는 모델
Milvus로 다중 모달 검색에 ColPali 사용 Milvus v2.4.x 문서
Milvus 벡터 데이터베이스 문서
Milvus v2.4.x 문서
milvus.io
Implement Multimodal RAG with ColPali and Vision Language Model Groq(Llava) and Qwen2-VL
Introduction
medium.com
vidore/colqwen2.5-v0.2 · Hugging Face
vidore/colqwen2.5-v0.2 · Hugging Face
ColQwen2.5: Visual Retriever based on Qwen2.5-VL-3B-Instruct with ColBERT strategy ColQwen is a model based on a novel model architecture and training strategy based on Vision Language Models (VLMs) to efficiently index documents from their visual features
huggingface.co
모델 모음
GitHub - illuin-tech/colpali: The code used to train and run inference with the ColVision models, e.g. ColPali, ColQwen2, and Co
The code used to train and run inference with the ColVision models, e.g. ColPali, ColQwen2, and ColSmol. - illuin-tech/colpali
github.com
vector db semantic search -> 동일한 키워드 없어도 검색 가능. 하나의 모달리티를 바탕으로 다른 모달리티 검색가능
chunk embedding: chunk 하나를 1개의 token으로 간주하고 전부 1로 맞추기(하나의 덩어리로 간주한다는 뜻)
그래야 유사도 검색이 가능. -> 990token, 1000 token 이런걸 다 150*990 -> 150*1로.. compression
근데 SBert, Selectra 쓰면 (1,Dim)으로 처음부터 만들어줌. 이건 CPU에서 돌리기 오래걸림. -> ollama embedding layer 쓰면 되긴 하는데 그럼 정보 loss가 엄청남.
원래 shape이 같아야 하므로
(seq,1)->(seq,dim), (dim, 1)..
Chunking
- 문서를 잘라서 넣어야 하는데.. 예쁘게 넣기가 어렵다! 그리고 여러 chunk를 고려해야 답할수 있는 경우도 있어서 어렵다.
방식
- Fixed_size: 문단 훼손 가능성 -> 1000개의 token이 아니고 1000 characters
- Recursive: 텍스트의 구조를 유지하는 선 안에서, 마침표뿐 아니라 여러 분할자를 사용해 텍스트를 나눔
- Document based: 마크다운, 코드, 테이블 들이 포함된 경우 구조에 맞게 텍스트를 분할(langchain에서는 unstrucured output 어쩌구가 있음)
- Semantic: 문장 사이의 Embedding 유사도 측정해서 분할 경계 설정
-> tokenizing 하고 chunking 해도 될듯
Chunk Overlapping
- 문맥 유지를 위해. 너무 많이는 x. 너무 많이하면 '등수'를 매기기 어려워짐
Retrieval
- TF-IDF(term frequency, inverse document frequency)
IDF: 모든 문서에서 자주 등장하는 단어는 중요도가 낮고, 특정 문서에서만 자주 등장하는 단어는 중요도 높음.
TF*IDF = 값이 높을수록 단어의 중요도 높음. 단어의 빈도와 문서 내에서의 중요도를 동시에 반영
- BM25 :TF의 영향을 줄임. 살짝 보정. IDF의 중요도를 더 많이 쳐줌. 희소한 단어에 높은 점수를 부여.
2016년 Elastic Search의 검색 scoring 기본 알고리즘을 TF/IDF에서 BM25로 변경 -> 그래서 특정 키워드에 좀 집중하는 경향이 있었음. 어떻게 보완?(유사DRI찾을때 이거 안쓰니까 괜찮을라나. 대책도 이거보다 semantic search를 더 잘할수있게 L2norm, cosine similarity등으로 바꿀수 있나 알아보기 )
Multi modality vector embedding또한 비지도학습으로 상이한 모달리티간 의미 연산 수행 가능
Indexing(검색) 속도 최적화 알고리즘
- Flat Index: Brute-force 방식임. 쿼리와 각 데이터사이 거리를 모두 계산하는 것. Euclidean/KNN/Cosine sim 등. -> 시간복잡도가 높음. 1~5만개까지는 가능
- Product Quantizer: 벡터를 같은 크기의 sub-vector N개로 분할 후 각 sub vector를 quantize하여 저장. 그럼 동일한 데이터셋을 더 작은 크기로 저장 가능. 속도 증가, 메모리사용량 감소
- LSH: chunk들을 임의의 cluster로 묶기. 같은 bucket에 속한 벡터들에 대해서만 비교. bucket 수 많을수록 결과는 좋지만 메모리소비량도 증가
- IVF(Inverted File Index): N개의 군집. Centroid 계산. Centroid와만 거리계산해서 해당 Cluster 속 벡터들에 대해서만 계산
- HNSW(Hierarchical Navigable Small World graph): N개의 층. threshold잡아서. 최상단층부터 탐색. 동일 층에서 거리를 더 좁힐 수 없으면 하층으로 이동. 가장 가까운 노드 발견시까지 반복.
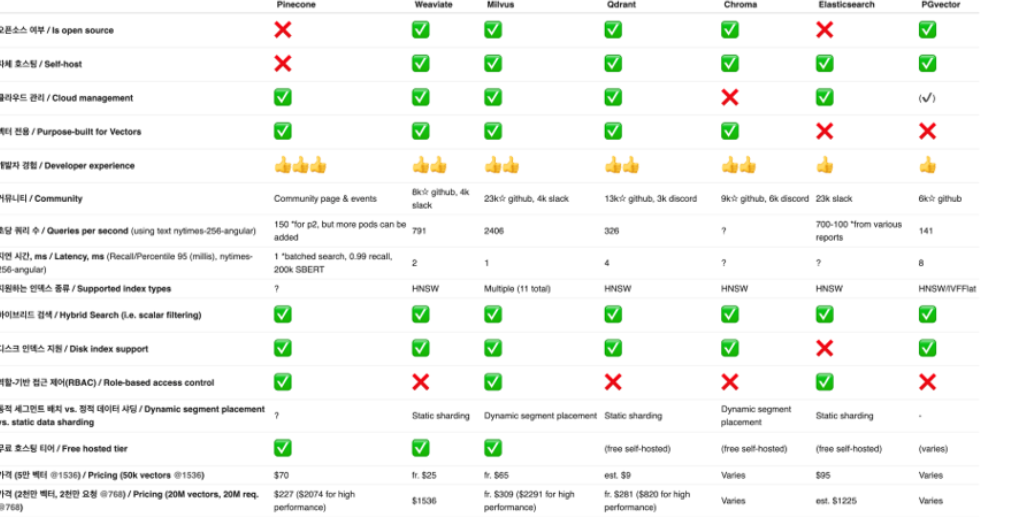
-> Vector DB의 option에 들어있음.
'AI > LLM' 카테고리의 다른 글
| Modular RAG (0) | 2025.02.25 |
|---|---|
| Reranker (0) | 2025.02.24 |
| 구조 (0) | 2025.02.24 |
| Adaptive RAG (0) | 2025.02.24 |
| Langchain (0) | 2025.02.10 |