Building a Chat App with LangChain, LLMs, and Streamlit for Complex SQL Database Interaction
Build and deploy a chat application for complex database interaction with LangChain agents.
towardsdatascience.com
본 포스팅은 위 게시글이 유용하여 한글로 번역 및 재구성한 내용입니다!
두 개의 포스팅으로 나누어 게시 예정입니다.
1. Postgresql 설정 및 데이터 전처리 - Airflow, Kafka, Spark, Docker 설정 ( 본 포스팅 )
2. Langchain, LLM, Streamlit 설정 - 자연어를 이해하고 sql query 로 변환해 Postgresql DB 탐색하기
0. 용어 및 Framework 소개
1. PostgreSQL DB
- PostgreSQL은 관계형 데이터베이스 관리 시스템(RDBMS)으로, 오픈 소스이며 확장 가능한 특징을 갖추고 있습니다.
- 전통적인 테이블 형태의 데이터를 저장하고 관리하며, SQL(Structured Query Language)을 사용하여 데이터를 조작할 수 있습니다.
- PostgreSQL은 ACID(Atomicity, Consistency, Isolation, Durability) 특성을 준수하며, 트랜잭션 처리와 같은 고급 데이터베이스 기능을 제공합니다.
- 다양한 데이터 형식을 지원하며, JSON, XML, 범위형, 지리 정보 시스템(GIS) 등의 확장 모듈을 제공합니다.
- 대규모의 데이터베이스 및 데이터 웨어하우스 시스템에서도 사용될 수 있습니다.
2. Streamlit
https://streamlit.io -> 배포 전 로컬에서 가볍게 시각화 해보기 좋아서, 저도 실제 추천 챗봇 만드는 프로젝트에서 활용중입니다!
Streamlit • A faster way to build and share data apps
Streamlit is an open-source Python framework for machine learning and data science teams. Create interactive data apps in minutes.
streamlit.io
- Streamlit은 파이썬으로 데이터 기반 웹 애플리케이션을 빠르게 만들 수 있는 오픈 소스 프레임워크입니다. 이를 사용하면 데이터 분석, 머신러닝 모델 시각화, 대시보드 등을 간편하게 웹 애플리케이션으로 변환할 수 있습니다.
- Streamlit은 사용자 친화적인 문법을 제공하여 개발자가 데이터와 모델을 시각적으로 표현하고 상호작용할 수 있도록 합니다. 사용자는 Python 스크립트를 사용하여 데이터를 불러오고 처리하고 시각화할 수 있으며, 이를 바탕으로 웹 애플리케이션을 빌드할 수 있습니다.
- 간단한 코드로 인터랙티브한 웹 애플리케이션을 만들 수 있습니다.
3. Langchain
https://www.langchain.com
LangChain
LangChain’s suite of products supports developers along each step of their development journey.
www.langchain.com
랭체인은 LLM을 사용하여 애플리케이션 생성을 단순화하도록 설계된 프레임워크이다. 언어 모델 통합 프레임워크로서 랭체인의 사용 사례는 문서 분석 및 요약, 챗봇, 코드 분석을 포함하여 일반적인 언어 모델의 사용 사례와 크게 겹친다. (출처: https://g.co/kgs/b9S39Sr)
1. 개요
End-to-End Data Engineering System on Real Data with Kafka, Spark, Airflow, Postgres, and Docker
Building a Practical Data Pipeline with Kafka, Spark, Airflow, Postgres, and Docker
towardsdatascience.com
이번 포스팅은 챗봇을 만들기 전 특정 데이터를 API로 불러와 처리 후 PostgreSQL DB에 넣는 데이터 엔지니어링 부분입니다. 데이터 Pipelining을 하는 것이죠. Spark, Kafka, Airflow 등등 데엔 필수적인 경험이 가능하겠어요.
- Kafka - 데이터 스트리밍
- Airflow - 오케스트레이션
- Spark - 데이터 transformation
- PostgreSQL - 데이터 저장
- Docker - 환경 설정 및 위의 툴 실행에 필요
이 첫 번째 파트는 데이터 엔지니어링이긴 하지만, 본인의 데이터 처리 관련 기술 스택을 조금 더 확장시키고자 하는 데이터 사이언티스트와 머신러닝 엔지니어들도 참고하면 좋을 것 같습니다. 이론적인 부분보다는 실용적으로 활용하는 방법에 초점을 맞춥니다. 따라서 자세한 설명은 생략하고 있습니다.
데이터 파이프라인 프로세스
- 데이터 스트리밍(Data Streaming) : 먼저, 데이터는 API에서부터 Kafka 토픽으로 스트리밍됩니다.
- 데이터 처리(Data Processing): Spark 작업이 Kafka 토픽에서 데이터를 소비하고 PostgreSQL 데이터베이스로 전송합니다.
- Airflow를 사용한 스케줄링: 스트리밍 작업과 Spark 작업은 Airflow를 사용하여 조정됩니다. 실제 시나리오에서는 Kafka 프로듀서가 API를 계속 확인할 것이지만, 데모 용도로는 Kafka 스트리밍 작업을 하루에 한 번 실행하도록 스케줄링하였습니다. 스트리밍이 완료되면 Spark 작업이 데이터를 처리하여 LLM 애플리케이션에서 사용할 수 있게 준비합니다.
이 모든 도구는 Docker를 사용하여 구축 및 실행되며, 구체적으로는 Docker-compose를 사용합니다.
API ->(stream data)-> Kafka Producer -> (Publish data) -> Kafka Topic -> (Consume data) -> SparkJob -> (Transfer data) -> PostgreSQL -> Airflow(전체 job scheduling)
2. Local 셋업
먼저 아래 Github repo를 본인의 로컬 머신에 clone 합니다.
git clone https://github.com/HamzaG737/data-engineering-project.git
프로젝트의 구조는 아래와 같습니다.
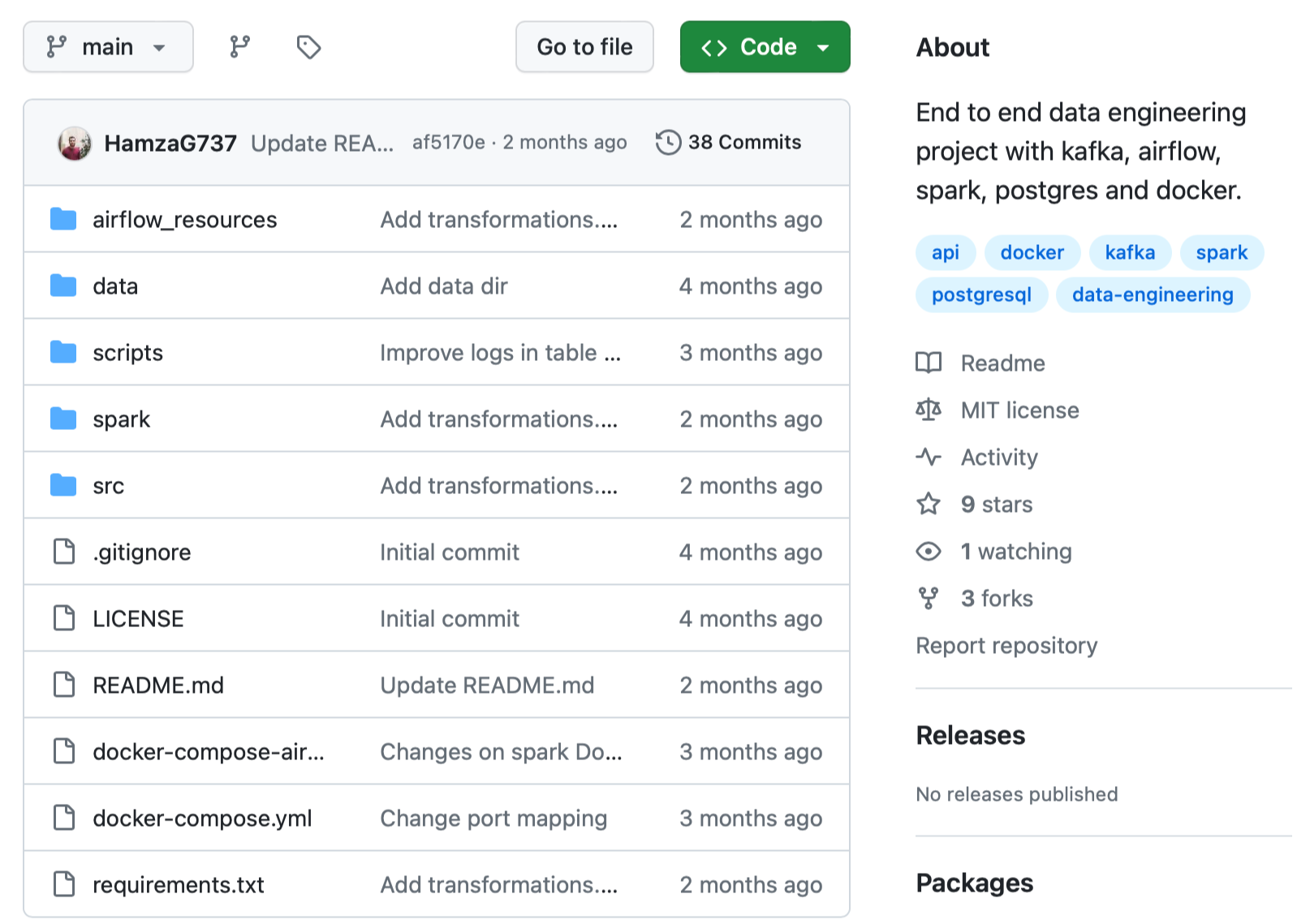
- airflow_resources 디렉터리의 custom Dockerfile은 airflow 세팅을 위한 것이고, 그 아래 dags 디렉터리는 task를 만들고 스케줄링 하기 위한 것입니다.
- data 디렉터리의 last_processed.json 파일은 Kafka 스트리밍 task를 위해 필수적인 파일입니다. 이후 이것의 역할을 말씀드리겠습니다.
- docker-compose-airflow.yaml (야믈 이라고 발음해요!) 파일은 Kafka 서비스를 구체화하고, docker 프록시를 포함하고 있습니다. 이 프록시는 Spark Jobs를 Airflow의 docker-operator를 통해 실행시킬 때 필수적입니다.
- spark 디렉터리는 spark 세팅을 위한 custom Dockerfile을 포함하고 있습니다.
- src 디렉터리는 애플리케이션 실행을 위한 파이썬 모듈들이 있습니다.
로컬 개발 환경을 설정하기 위해, requirements.txt 속의 파이썬 패키지를 모두 설치해줍니다. (새로운 가상환경에 설치하는 것을 추천드려요!) psycopg2-binary 패키지만 꼭 설치해주면 됩니다. 한번에 모두 설치하고 싶다면, 아래 코드를 통해 설치하시면 됩니다.
pip install -r requirements.txt
#requirements.txt
kafka_python==2.0.2
psycopg2-binary==2.9.9
apache-airflow==2.7.3
pyspark==3.5.0
unidecode==1.3.73. API에 대해서
본 프로젝트에서 활용할 API는 RappelConso라는 프랑스 공공서비스 API입니다. 프랑스 세관 제품 리콜 데이터이고, 프랑스어로 되어 있으며(프랑스어 오랜만에 보니 반갑네요 ㅋ.ㅋ) 31개의 컬럼(==필드)으로 구성돼 있습니다. 그 중 중요한 컬럼들은 아래와 같습니다:
- reference_fiche (reference sheet): Unique identifier of the recalled product. It will act as the primary key of our Postgres database later.
- categorie_de_produit (Product category): For instance food, electrical appliance, tools, transport means, etc …
- sous_categorie_de_produit (Product sub-category): For instance we can have meat, dairy products, cereals as sub-categories for the food category.
- motif_de_rappel (Reason for recall): Self explanatory and one of the most important fields.
- date_de_publication which translates to the publication date.
- risques_encourus_par_le_consommateur which contains the risks that the consumer may encounter when using the product.
- There are also several fields that correspond to different links, such as link to product image, link to the distributers list, etc..
이 link 에서 자세한 내용을 확인 가능합니다.
데이터 정제
이러한 데이터 컬럼을 중요한 몇가지 방법을 통해 정제할 건데요, src/kafka_client/transformations.py 코드에서 세부적인 정제 방법을 확인가능합니다.
- ndeg_de_version, rappelguid같은 열들은 버전 관리 시스템의 일부였지만, 이 프로젝트에선 필요하지 않아 제거했습니다.
- 소비자 위험과 관련된 열인 risques_encourus_par_le_consommateur와 description_complementaire_du_risque는 제품 위험을 더 명확하게 파악하기 위해 결합되었습니다.
- 상품의 마케팅 기간을 나타내는 date_debut_fin_de_commercialisation 열은 두 개의 별도 열로 분할되었습니다. 이러한 분할로 제품의 마케팅 시작 또는 종료에 대한 쿼리가 더 쉬워졌습니다.
- 링크, 참조 번호 및 날짜를 제외한 모든 열에서 악성(accents, é 같이 프랑스어 위에 붙은 기호 )를 제거했습니다. 일부 텍스트 처리 도구가 악성 문자에 대해 처리하는 데 어려움을 겪는 경우가 있기 때문에 필수적입니다.
4. Kafka Streaming
사실 저(역자)는 이 부분이 제일 궁금했습니다! 이전까지 카프카를 어디에 쓰는지 정도만 알고 있었고 실제로 써 본적이 없었거든요. 저는 모델 자체만 개발하는 데 머물러있었다보니 이런 데이터 엔지니어링까지 해 보고싶었습니다. 그래서 해보게 되었어요 😊
스트리밍 작업을 실행할 때마다 API에서 모든 데이터를 보내는 것을 피하기 위해, 최신 스트리밍의 마지막 publication date를 포함하는 로컬 json 파일을 정의합니다. 그런 다음 이 날짜를 새로운 스트리밍 작업의 시작 날짜로 사용합니다.
예를 들어, 가장 최근에 리콜된 제품의 publication date가 2023년 11월 22일이라고 가정해 보겠습니다. 이 날짜 이전에 이미 PostgreSQL 데이터베이스에 저장된 모든 제품 정보를 다루었다는 가정을 하면, 11월 22일부터 데이터를 스트리밍하면 됩니다. (11월 22일의 모든 데이터를 처리하지 않은 시나리오가 있을 수 있으므로 중복에 유의해야해요)
./data/last_processed.json 파일 속의 데이터 포맷은 다음과 같습니다.
{last_processed:"2023-11-22"}
이 파일을 empty json으로 설정하면 스트리밍 작업이 모든 api기록을 (약 10000개) 처리하도록 하는 것입니다. 실제 production 시에는 로컬 파일에 마지막 처리 날짜를 저장하는 이 방식이 적합하지 않을 수 있으며, 외부 데이터베이스나 객체 저장 서비스를 활용하는 다른 방식이 더 적절할 수 있습니다. 카프카 스트리밍 코드는 ./src/kafka_client/kafka_stream_data.py에서 볼 수 있으며, API에서 데이터를 쿼리하고 변환하며, 잠재적 중복을 제거하고, 마지막 publication date를 업데이트하고,Kafka Producer를 통해 데이터를 제공하는 과정을 포함합니다.
다음 단계는 아래 docker-compose에서 정의된 카프카 서비스를 실행하는 것입니다:
version: '3'
services:
kafka:
image: 'bitnami/kafka:latest'
ports:
- '9094:9094'
networks:
- airflow-kafka
environment:
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093,EXTERNAL://:9094
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://kafka:9092,EXTERNAL://localhost:9094
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,EXTERNAL:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
volumes:
- ./kafka:/bitnami/kafka
kafka-ui:
container_name: kafka-ui-1
image: provectuslabs/kafka-ui:latest
ports:
- 8800:8080
depends_on:
- kafka
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: PLAINTEXT://kafka:9092
DYNAMIC_CONFIG_ENABLED: 'true'
networks:
- airflow-kafka
networks:
airflow-kafka:
external: true
이 파일에서 중요하게 봐야 할 부분은 아래와 같습니다.
- 카프카 서비스는 bitnami/kafka 기본 이미지를 사용합니다.
- 본 프로젝트는 크기가 작기 때문에 하나의 Broker만으로 실행가능하여 이렇게 구성하였습니다. 카프카 브로커는 프로듀서(데이터의 원본)로부터 메시지를 수신하고 이러한 메시지를 저장하며, 소비자(데이터의 수신자 또는 최종 사용자)에게 전달합니다. 브로커는 클러스터 내부 통신을 위해 포트 9092를 활용하며, 클러스터 외부 통신을 위해 포트 9094를 활용합니다. 이를 통해 도커 네트워크 외부의 클라이언트가 카프카 브로커에 연결할 수 있습니다.
- volumes 부분에서는 지역 디렉터리 kafka를 docker 컨테이너 디렉터리 /bitnami/kafka에 매핑하여 데이터 지속성과 호스트 시스템에서 카프카 데이터를 검사할 수 있도록합니다.
- 우리는 kafka-ui 서비스를 provectuslabs/kafka-ui:latest 도커 이미지를 사용하도록 설정합니다. 이는 카프카 클러스터와 상호 작용하기 위한 사용자 인터페이스를 제공합니다. 이는 특히 카프카 토픽과 메시지를 모니터링하고 관리하는 데 유용합니다.
- Kafka와 Airflow 간의 통신을 보장하기 위해 외부 서비스로 실행될 airflow-kafka 외부 네트워크를 사용할 것입니다.
Kafka 서비스를 실행하기 전, 아래 명령어를 이용하여 airflow - kafka 네트워크를 만들어줍니다.
docker network create airflow-kafka
이제 Kafka 서비스를 실행하면 됩니다.
docker-compose up
서비스를 시작하고 나면 주소창에 http://localhost:8800/ 를 입력해 kafka-ui에 들어가봅니다.
####실제 해 보고 Kafka UI 이미지 삽입 #####
이제 API 메세지를 포함하고 있는 우리의 topic을 생성할 것입니다. 화면 왼쪽의 Topics를 누르고, 왼쪽 위에서 topic 을 add 합니다. topic 이름은 rappel_conso라고 짓고, Broker를 하나만 활용하기 때문에 replication factor는 1로 설정합니다. 그리고 한 번에 한 개의 consumer 쓰레드만 사용할 것이므로 partitions도 1로 설정합니다. (parallelism, 즉 병렬화 하지 않는다는 뜻)
마지막으로, 데이터를 보존하기 위한 time은 1시간 정도의 작은 숫자로 설정합니다. 왜냐하면 kafka streaming task 이후 바로 spark job을 실행할거기 때문에, 데이터를 오래 보유하고 있을 필요가 없습니다!
5. Postgres 셋업
Spark와 Airflow 환경설정 이전에, 우리의 API 데이터를 저장할 Postgres DB를 만들 것입니다. 이를 위해 본 프로젝트에서는 pgadmin 4 툴을 활용하지만, 다른 개발 플랫폼을 활용해도 됩니다!
아래 링크를 방문하여 OS에 따라 postgres와 pgadmin을 다운받을 수 있습니다.
https://www.postgresql.org/download/
PostgreSQL: Downloads
www.postgresql.org
설치할 때 입력한 비밀번호를 잘 기억해 놓고, port는 5432로 두시면 됩니다. 설치가 완료되면 pgadmin을 실행해서 아래와 같은 창을 확인가능합니다.
### 실행 후 사진 삽입 ####
컬럼이 너무 많기 때문에, psycopg2라는 Python용 PostgreSQL DB 어댑터로 테이블을 만들고 컬럼이름을 추가해 줄겁니다. 스크립트 내의 POSTGRES_PASSWORD 라는 환경변수로 본인의 비밀번호를 수정해서 저장해놓으시면 됩니다.
python scripts/create_table.py
6. Spark 셋업
이제 spark job에 대해 조금더 자세히 보겠습니다. Kafka topic인 rappel_conso에서부터 Postgres table인 rappel_conso_table로 데이터를 stream 시키는 것이 목적입니다. src/spark_pgsql/spark_streaming.py 파일에서 소스코드를 확인가능합니다. 중간에 로그도 남겨주네요..
from pyspark.sql import SparkSession
from pyspark.sql.types import (
StructType,
StructField,
StringType,
)
from pyspark.sql.functions import from_json, col
from src.constants import POSTGRES_URL, POSTGRES_PROPERTIES, DB_FIELDS
import logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s:%(funcName)s:%(levelname)s:%(message)s"
)
def create_spark_session() -> SparkSession:
spark = (
SparkSession.builder.appName("PostgreSQL Connection with PySpark")
.config(
"spark.jars.packages",
"org.postgresql:postgresql:42.5.4,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0",
)
.getOrCreate()
)
logging.info("Spark session created successfully")
return spark
def create_initial_dataframe(spark_session):
"""
Reads the streaming data and creates the initial dataframe accordingly.
"""
try:
# Gets the streaming data from topic random_names
df = (
spark_session.readStream.format("kafka")
.option("kafka.bootstrap.servers", "kafka:9092")
.option("subscribe", "rappel_conso")
.option("startingOffsets", "earliest")
.load()
)
logging.info("Initial dataframe created successfully")
except Exception as e:
logging.warning(f"Initial dataframe couldn't be created due to exception: {e}")
raise
return df
def create_final_dataframe(df):
"""
Modifies the initial dataframe, and creates the final dataframe.
"""
schema = StructType(
[StructField(field_name, StringType(), True) for field_name in DB_FIELDS]
)
df_out = (
df.selectExpr("CAST(value AS STRING)")
.select(from_json(col("value"), schema).alias("data"))
.select("data.*")
)
return df_out
def start_streaming(df_parsed, spark):
"""
Starts the streaming to table spark_streaming.rappel_conso in postgres
"""
# Read existing data from PostgreSQL
existing_data_df = spark.read.jdbc(
POSTGRES_URL, "rappel_conso", properties=POSTGRES_PROPERTIES
)
unique_column = "reference_fiche"
logging.info("Start streaming ...")
query = df_parsed.writeStream.foreachBatch(
lambda batch_df, _: (
batch_df.join(
existing_data_df, batch_df[unique_column] == existing_data_df[unique_column], "leftanti"
)
.write.jdbc(
POSTGRES_URL, "rappel_conso", "append", properties=POSTGRES_PROPERTIES
)
)
).trigger(once=True) \
.start()
return query.awaitTermination()
def write_to_postgres():
spark = create_spark_session()
df = create_initial_dataframe(spark)
df_final = create_final_dataframe(df)
start_streaming(df_final, spark=spark)
if __name__ == "__main__":
write_to_postgres()
코드를 세부적으로 뜯어서 보면, 아래와 같습니다.
- create_spark_session 함수: Spark Session 생성
- create_initial_dataframe 함수: Spark의 구조화된 스트리밍을 사용하여 Kafka 토픽에서 스트리밍 데이터 입력
- create_final_dataframe 함수: 데이터가 입력되면 이 함수가 json 형태의 데이터에 DB 스키마를 적용함
- start_streaming 함수: DB에 존재하는 데이터를 읽고 입력된 stream과 비교해서 새로운 레코드로 저장
나중에 Airflow DockerOperator로 이것을 실행시킬 것입니다. Spark job을 실행시키기 위해 필요한 도커 이미지를 생성해봅시다.
아래는 Dockerfile 의 내용입니다. bitnami/spark 를 베이스 이미지로 활용하고, Spark를 파이썬으로 실행할 때 필요한 py4j도 설치합니다. POSTGRES_DOCKER_USER와 POSTGRES_PASSWORD 환경변수는 PostgreSQL 연결 시 사용됩니다. 이 DB는 호스트 머신에 있기 때문에 host.docker.internal를 user로 사용합니다. 이렇게 하면 Docker container가 host에 있는 서비스(이 프로젝트에서는 PostgreSQL)에 접근 가능하게 합니다.
FROM bitnami/spark:latest
WORKDIR /opt/bitnami/spark
RUN pip install py4j
COPY ./src/spark_pgsql/spark_streaming.py ./spark_streaming.py
COPY ./src/constants.py ./src/constants.py
ENV POSTGRES_DOCKER_USER=host.docker.internal
ARG POSTGRES_PASSWORD
ENV POSTGRES_PASSWORD=$POSTGRES_PASSWORD이렇게 DB 패스워드를 빌드할 때 넘기는 방법은 보안상 좋지 않습니다. 실제로 활용 시에는 Docker BuildKit같은 조금더 보안이 강화된 방법을 고려하는 것을 추천합니다!
이제 아래 명령어로 Docker Image를 빌드하면 됩니다. 이 이미지는 본 프로젝트의 Spark job을 돌리기 위한 모든 것을 포함하고 있어서, Airflow의 DockerOperator가 job을 실행할 때 활용될것입니다. 실제 실행시킬 때 Password부분을 본인의 패스워드로 수정해서 활용하세요.
docker build -f spark/Dockerfile -t rappel-conso/spark:latest --build-arg POSTGRES_PASSWORD=$POSTGRES_PASSWORD .
7. Airflow
Apache Airflow는 데이터 파이프라인에서 orchestration 툴로 활용됩니다. 이는 작업의 일정을 예약하고 관리하며, 지정된 순서와 정의된 조건 하에서 실행되도록 하는 역할을 합니다. 우리 시스템에서는 Airflow가 Kafka로의 스트리밍에서부터 Spark로의 처리까지 데이터 흐름을 자동화하는 데 사용됩니다.
Airflow DAG
작업의 순서와 종속성을 개요화하는 방향성 비순환 그래프(DAG)를 살펴보겠습니다. 이를 통해 Airflow가 작업의 실행을 관리할 수 있습니다.
start_date = datetime.today() - timedelta(days=1)
default_args = {
"owner": "airflow",
"start_date": start_date,
"retries": 1, # number of retries before failing the task
"retry_delay": timedelta(seconds=5),
}
with DAG(
dag_id="kafka_spark_dag",
default_args=default_args,
schedule_interval=timedelta(days=1),
catchup=False,
) as dag:
kafka_stream_task = PythonOperator(
task_id="kafka_data_stream",
python_callable=stream,
dag=dag,
)
spark_stream_task = DockerOperator(
task_id="pyspark_consumer",
image="rappel-conso/spark:latest",
api_version="auto",
auto_remove=True,
command="./bin/spark-submit --master local[*] --packages org.postgresql:postgresql:42.5.4,org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.0 ./spark_streaming.py",
docker_url='tcp://docker-proxy:2375',
environment={'SPARK_LOCAL_HOSTNAME': 'localhost'},
network_mode="airflow-kafka",
dag=dag,
)
kafka_stream_task >> spark_stream_task
다음은 이 구성에서 주요 요소들입니다.
- 작업은 매일 실행되도록 설정되어 있습니다.
- 첫 번째 작업은 Kafka 스트림 작업입니다. PythonOperator를 사용하여 실행되며, Kafka 스트리밍 함수를 실행합니다. 이 작업은 RappelConso API에서 데이터를 Kafka 주제로 스트리밍하여 데이터 처리 워크플로우를 시작합니다.
- 다음 작업은 Spark 스트림 작업입니다. 이 작업은 실행을 위해 DockerOperator를 사용합니다. 사용자 정의 Spark 이미지가 포함된 Docker 컨테이너를 실행하여 Kafka에서 받은 데이터를 처리합니다.
- 작업은 순차적으로 배치되어 있으며, Kafka 스트리밍 작업이 Spark 처리 작업보다 먼저 실행됩니다. 이 순서는 데이터가 Spark에서 처리되기 전에 먼저 Kafka로 스트리밍되고 로드되도록 보장하기 위해 중요합니다.
DockerOperator
Docker operator를 사용하면 작업에 해당하는 docker-container를 실행할 수 있습니다. 이 접근 방식의 주요 장점은 패키지 관리가 더 쉽고, 더 나은 격리 및 향상된 테스트 가능성입니다. 이 operator의 사용법을 spark 스트리밍 작업으로 설명하겠습니다. 다음은 spark 스트리밍 작업에 대한 docker operator에 대한 몇 가지 주요 세부 정보입니다:
- Spark Set-up 섹션에서 지정된 rappel-conso/spark:latest 이미지를 사용할 것입니다.
- 명령은 컨테이너 내부에서 Spark submit 명령을 실행하며, 마스터를 로컬로 지정하고, PostgreSQL 및 Kafka 통합에 필요한 패키지를 포함하며, Spark 작업의 로직이 포함된 spark_streaming.py 스크립트를 지정합니다.
- docker_url은 도커 데몬을 실행하는 호스트의 URL을 나타냅니다. 자연스러운 해결책은 unix://var/run/docker.sock로 설정하고 var/run/docker.sock을 airflow 도커 컨테이너에 마운트하는 것입니다. 이 접근 방식의 문제점 중 하나는 airflow 컨테이너 내에서 소켓 파일을 사용할 권한이 없다는 것입니다. 일반적인 해결책인 chmod 777 var/run/docker.sock을 사용하면 상당한 보안 위험이 발생합니다. 이를 해결하기 위해 bobrik/socat을 docker-proxy로 사용하는 보다 안전한 솔루션을 구현했습니다. 이 프록시는 Docker Compose 서비스에서 정의되며 TCP 포트 2375에서 수신하고 요청을 Docker 소켓으로 전달합니다.
#DockerOperator
docker-proxy:
image: bobrik/socat
command: "TCP4-LISTEN:2375,fork,reuseaddr UNIX-CONNECT:/var/run/docker.sock"
ports:
- "2376:2375"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
networks:
- airflow-kafka
DockerOperator에서는 tcp://docker-proxy:2375 URL을 통해 호스트 도커의 /var/run/docker.sock에 액세스할 수 있습니다.
- 마지막으로 네트워크 모드를 airflow-kafka로 설정합니다. 이를 통해 프록시 및 카프카를 실행하는 도커와 동일한 네트워크를 사용할 수 있습니다. 이것은 Spark 작업이 카프카 주제에서 데이터를 소비하기 때문에 두 컨테이너가 통신할 수 있도록 보장해야 하기 때문에 중요합니다.
DAG의 논리를 정의했으니, 이제 docker-compose-airflow.yaml 파일에서 airflow 서비스 구성을 이해해 봅시다.
Airflow 구성
Airflow를 위한 compose 파일은 공식 Apache Airflow docker-compose 파일을 수정하였습니다. 원본 파일은 이 링크를 방문하여 확인할 수 있습니다. https://airflow.apache.org/docs/apache-airflow/2.7.3/docker-compose.yaml
이 포스팅에서 지적한 대로, 이 제안된 Airflow 버전은 주로 코어 실행자가 분산 및 대규모 데이터 처리 작업에 적합한 CeleryExecutor로 설정되어 있기 때문에 리소스를 많이 사용합니다. 우리가 하는 작업은 작으므로 단일 노드 LocalExecutor를 사용하면 충분합니다. 다음은 Airflow의 도커 컴포즈 구성에서 우리가 한 변경 사항의 개요입니다.
- 환경 변수 AIRFLOW__CORE__EXECUTOR를 LocalExecutor로 설정했습니다.
- Celery 실행자에만 작동하는 서비스인 airflow-worker 및 flower를 제거했습니다. 또한 Celery의 백엔드로 작동하는 Redis 캐싱 서비스도 제거했습니다. airflow-triggerer도 사용하지 않을 것이므로 제거했습니다.
- 남은 서비스인 스케줄러 및 웹 서버에 대한 기본 이미지 ${AIRFLOW_IMAGE_NAME:-apache/airflow:2.7.3}를 사용자 정의 이미지로 대체했습니다. 이 사용자 정의 이미지는 도커 컴포즈를 실행할 때 빌드됩니다.
#custom image
version: '3.8'
x-airflow-common:
&airflow-common
build:
context: .
dockerfile: ./airflow_resources/Dockerfile
image: de-project/airflow:latest
- Airflow에서 필요한 볼륨을 마운트했습니다. AIRFLOW_PROJ_DIR은 나중에 정의할 Airflow 프로젝트 디렉토리를 지정합니다. 또한 카프카 부트스트랩 서버와 통신할 수 있도록 네트워크를 airflow-kafka로 설정했습니다.
volumes:
- ${AIRFLOW_PROJ_DIR:-.}/dags:/opt/airflow/dags
- ${AIRFLOW_PROJ_DIR:-.}/logs:/opt/airflow/logs
- ${AIRFLOW_PROJ_DIR:-.}/config:/opt/airflow/config
- ./src:/opt/airflow/dags/src
- ./data/last_processed.json:/opt/airflow/data/last_processed.json
user: "${AIRFLOW_UID:-50000}:0"
networks:
- airflow-kafka그리고 docker-compose에서 사용된 환경변수 몇개를 만들어줍니다.
echo -e "AIRFLOW_UID=$(id -u)\nAIRFLOW_PROJ_DIR=\"./airflow_resources\"" > .env
여기서 AIRFLOW_UID는 Airflow 컨테이너의 사용자 ID를 나타내며 AIRFLOW_PROJ_DIR은 Airflow 프로젝트 디렉토리를 나타냅니다. 이제 모든 준비가 되었습니다. Airflow 서비스를 실행하려면 다음 명령어를 입력하세요:
docker compose -f docker-compose-airflow.yaml up
그리고 http://localhost:8080 로 접속해 Airflow User Interface를 확인해봅니다.
#####사진삽입####
기본적으로 사용자 이름과 비밀번호는 모두 airflow입니다. 로그인한 후에는 airflow와 함께 제공되는 Dags 목록이 표시됩니다. 우리 프로젝트의 dag인 kafka_spark_dag을 찾아 클릭하세요. 그리고 DAG:kafka_spark_dag 옆의 버튼을 눌러 task를 시작(활성화) 가능합니다.
이제 Graph 탭에서 task의 상태 확인이 가능합니다. (초록색이면 실행 중인것).
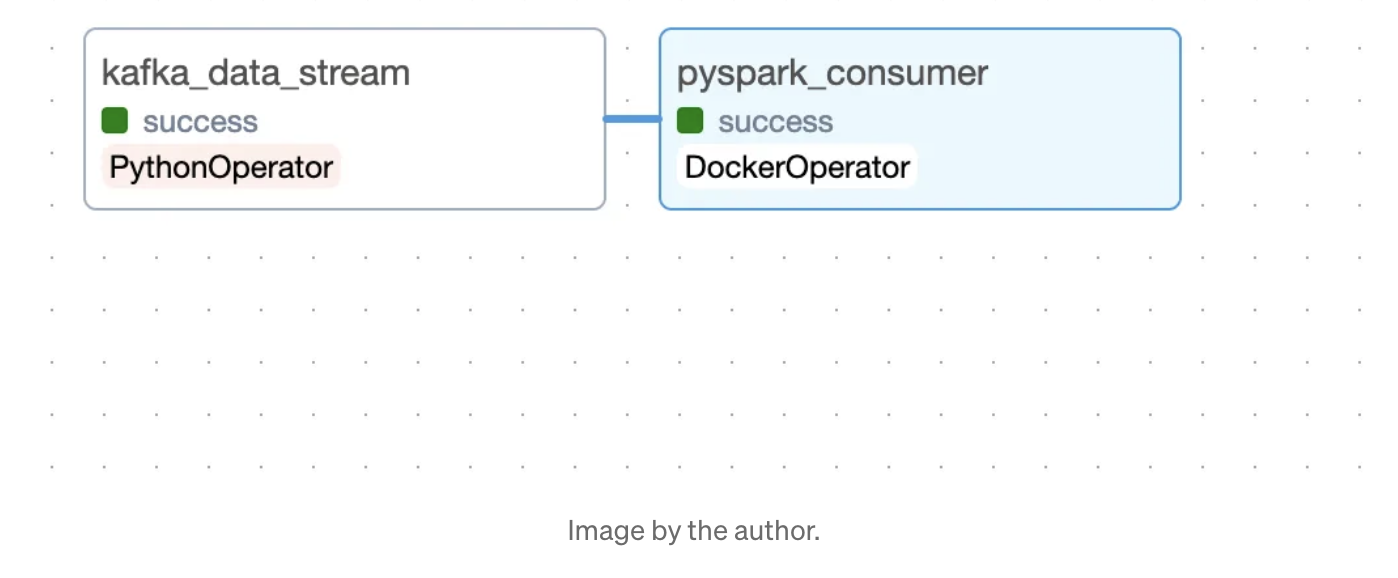
rappel_conso_table 에 데이터가 제대로 들어갔는지 확인하려면 pgAdmin Query tool로 아래 명령어를 실행해보면 됩니다.
SELECT count(*) FROM rappel_conso_table
-끝-
다음 포스팅에서는 Langchain, LLM, Streamlit으로 DB기반 챗봇을 만들어보겠습니다.
'AI > LLM' 카테고리의 다른 글
| 구조 (0) | 2025.02.24 |
|---|---|
| Adaptive RAG (0) | 2025.02.24 |
| Langchain (0) | 2025.02.10 |
| tool calling (0) | 2025.02.10 |
| [LLM] 데이터 엔지니어링부터 LLM활용 DB검색 챗봇 만들기- 2.Langchain, LLM, Streamlit 설정 - 자연어를 이해하고 sql query 로 변환해 Postgresql DB 탐색하기 (7) | 2024.03.08 |