[Recommender Systems] A Framework for Collaborative, Content-Based andDemographic Filtering
Main Points
1. What is the problem that the paper wants to solve? Why is it difficult?
선택지가 너무 많아 추천이 필요. 검색엔진은 수천 개의 관련 사이트 찾아줌. 뉴스도 수백 개
content based filtering, collaborative filtering 방식. 기존 방식들은 장점이 상호배타적임.
특정 웹 페이지를 높게 평가한 사용자들에 대한 demographic information(인구통계학적방식)을 고려해 추천하고싶다.
2. What is the solution? What is the main idea?
Intelligent agents -이 결과들을 개인과의 관련도순으로 정렬하는 방식. 유저의 평점과 유저프로필 사용.
여러 접근법들을 합칠거다!
content based : 아이템의 정보.
demographic based:
collaborative: set of people에 대한 set of items의/혹은 set of descriotions of the people의 ratings
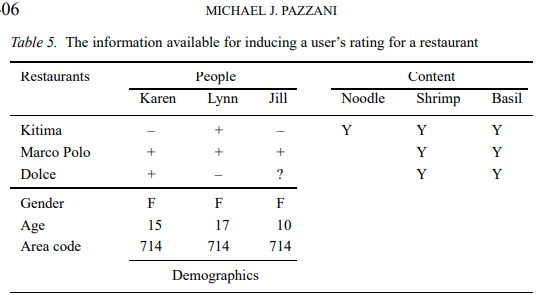
3. What is the result?
Strengths
1. What is the main novelty that enabled the solution?
- 사용자의 하나의 정보만을 사용하는 것 보다 여러 정보를 결합해서 쓸 때 정확도가 높다는 것을 증명. (처음?)
- binary features와 binary ratings만 썼다. -> TF IDF등을 쓰면 연속적인 값에도 가능.
- 기존: content만. 여기선: collaboration
- 각 알고리즘들의 랭킹을 합치면 정확도 향상
2. What are the good aspects of the paper? Did you learn something from the paper?
ㄱ. 3개의 알고리즘을 2가지 method 이용해 하나의 프레임워크로 통합.
1) collaboration via content: 유저간 유사도를 기존과 다른 방식으로 측정
2) 알고리즘간의 추천결과 합의
ㄴ. 이쪽에 썼던 접근법을 다른곳에. (EX. sementic indexing에서 사용한 SVD를 인구통계학적 필터링 방식에도 새로운 차원으로 사용 가능. 또한 유저가 웹페이지에 평점 매긴 것에도 사용 가능.. content based filtering에서 만들어진 행렬의 차원을 축소해 줌)
3. What is the impact of the paper?
Future Improvements
1. Are there weaknesses parts in the paper? How can you improve it?
ranking의 ordering에만 집중했음. (그래도 성능은 좋더라)
2. How can you extend the paper?
3. How can you apply the technique to other data/problem?
기존의 방식과 유사하긴 함. web에 대한...(Fab system) 근데 여기선 추천 알고리즘에 집중. 그리고 Fab에서는 단순히 content based만 사용했다면, 여기선 collaborative..